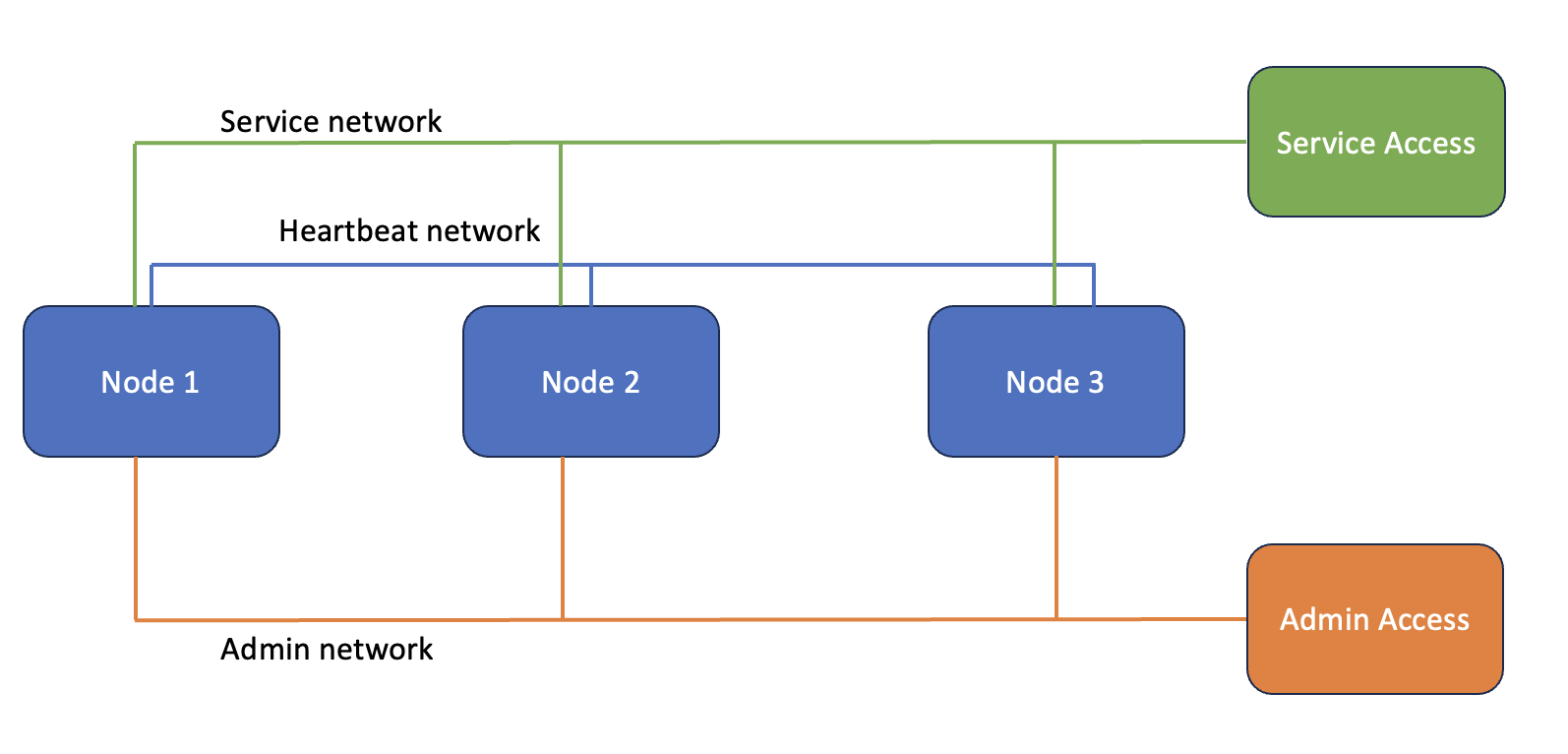
- ASIX Administració de Sistemes Informàtics i Xarxes
-
Tots els mòduls del cicle
- MP01 Implantació de sistemes operatius
-
Totes les UFs del modul
- MP02 Gestió de bases de dades
-
Totes les UFs del modul
- MP03 Programació bàsica
-
Totes les UFs del modul
- MP04 Llenguatges de marques i sistemes de gestió d'informació
-
Totes les UFs del modul
- MP05 Fonaments de maquinari
-
Totes les UFs del modul
- MP06 Administració de sistemes operatius
-
Totes les UFs del modul
- MP07 Planificació i administració de xarxes
-
Totes les UFs del modul
- MP08 Serveis de xarxa i Internet
-
Totes les UFs del modul
- MP09 Implantació d'aplicacions web
-
Totes les UFs del modul
- MP10 Administració de sistemes gestors de bases de dades
-
Totes les UFs del modul
- MP11 Seguretat i alta disponibilitat
-
Totes les UFs del modul
- MP12 Formació i orientació laboral
-
Totes les UFs del modul
- MP13 Empresa i iniciativa emprenedora
-
Totes les UFs del modul
- MP14 Projecte
-
Totes les UFs del modul
- DAM Desenvolupament d’aplicacions multiplataforma
-
Tots els mòduls del cicle
- MP01 Sistemes informàtics
-
Totes les UFs del modul
- MP02 Bases de dades
-
Totes les UFs del modul
- MP03 Programació bàsica
-
Totes les UFs del modul
- MP04 Llenguatges de marques i sistemes de gestió d'informació
-
Totes les UFs del modul
- MP05 Entorns de desenvolupament
-
Totes les UFs del modul
- MP06 Accés a dades
-
Totes les UFs del modul
- MP07 Desenvolupament d’interfícies
-
Totes les UFs del modul
- MP08 Programació multimèdia i dispositius mòbils
-
Totes les UFs del modul
- MP09 Programació de serveis i processos
-
Totes les UFs del modul
- MP10 Sistemes de gestió empresarial
-
Totes les UFs del modul
- MP11 Formació i orientació laboral
-
Totes les UFs del modul
- MP12 Empresa i iniciativa emprenedora
-
Totes les UFs del modul
- MP13 Projecte de síntesi
-
Totes les UFs del modul
- MPDual Mòdul Dual / Projecte
-
- DAW Desenvolupament d’aplicacions web
-
Tots els mòduls del cicle
- MP01 Sistemes informàtics
-
Totes les UFs del modul
- MP02 Bases de dades
-
Totes les UFs del modul
- MP03 Programació
-
Totes les UFs del modul
- MP04 Llenguatge de marques i sistemes de gestió d’informació
-
Totes les UFs del modul
- MP05 Entorns de desenvolupament
-
Totes les UFs del modul
- MP06 Desenvolupament web en entorn client
-
Totes les UFs del modul
- MP07 Desenvolupament web en entorn servidor
-
Totes les UFs del modul
- MP08 Desplegament d'aplicacions web
-
Totes les UFs del modul
- MP09 Disseny d'interfícies web
-
Totes les UFs del modul
- MP10 Formació i Orientació Laboral
-
Totes les UFs del modul
- MP11 Empresa i iniciativa emprenedora
-
Totes les UFs del modul
- MP12 Projecte de síntesi
-
Totes les UFs del modul
- SMX Sistemes Microinformàtics i Xarxes
-
Tots els mòduls del cicle
- MP01 Muntatge i manteniment d’equips
-
Totes les UFs del modul
- MP02 Sistemes Operatius Monolloc
-
Totes les UFs del modul
- MP03 Aplicacions ofimàtiques
-
Totes les UFs del modul
- MP04 Sistemes operatius en xarxa
-
Totes les UFs del modul
- MP05 Xarxes locals
-
Totes les UFs del modul
- MP06 Seguretat informàtica
-
Totes les UFs del modul
- MP07 Serveis de xarxa
-
Totes les UFs del modul
- MP08 Aplicacions Web
-
Totes les UFs del modul
- MP09 Formació i Orientació Laboral
-
Totes les UFs del modul
- MP10 Empresa i iniciativa emprenedora
-
Totes les UFs del modul
- MP11 Anglès
-
Totes les UFs del modul
- MP12 Síntesi
-
Totes les UFs del modul
- CETI Ciberseguretat en Entorns de les Tecnologies de la Informació
-
Tots els mòduls del cicle
- CiberOT Ciberseguretat en Entorns d'Operació
-
Tots els mòduls del cicle