Taula de continguts
Cluster amb Pace Maker i Corosync
Introducció
De vegades necessitem crear un cluster amb més seguretat que un contenidor o màquina virtual, ja que en cas que ens guanyin accés a la màquina física, si muntem un entorn amb docker en alta disponibilitat, ens el poden tombar igualment, es per això que en aquests casos podem optar per un cluster hardware. Exemple d’això poden ser muntar un cluster de firewall o de routing.
En aquests casos, necessitem, com a mínim, dos màquines físiques el més semblants possibles, ja que el servei haurà de treballar indistintament en una o en l’altre.
Conceptes previs
De totes maneres, i al igual que en qualsevol altre cluster, es molt recomanable fer el cluster amb 3 nodes. Això es degut a que, en cas que hi hagi una desconnexió de qualsevol dels nodes del cluster, el tercer cluster serveix per tenir quorum. També necessitarem, en cas que el node amb el servei quedi bloquejat poder reiniciar-lo des de un altre node, per això primer definirem conceptes:
- Quorum: Quantitat mínima de nodes o membres necessaris perque un servei funcioni correctament. Per tal que un sistema sigui minimament fiable, el minim de nodes necessaris es 3, això es degut a, en cas d'aillament de un dels nodes, aquest podrà definir si el problema es propi o forani, si pot accedir a un dels altres 2 nodes.
- Split-Brain: Situació del cluster on dos o més nodes poden considerar-se actius alhora e intentar asumir el control dels recursos compartits al mateix moment. Això pot generar incosistències i conflictes a les dades.
- STONITH (Shot The Other Node In The Head): Mecanisme del cluster per protecció i recuperació davant de fallades. Es una tècnique que garantitza la disponibilitat i la integritat forçant l'apagada de un node considerat inestable o en fallida. Es un mecanisme pensat per evitar que diferents nodes del cluster puguin accedir als mateixos recursos de forma simultània. Això podria derivar en una situació coneguda com Split-Brain, Aquesta es una mesura extrema que força l'apagada de una màquina, i ha d'evitar, en la mesura del possible apagar un node que funcioni correctament.
- Heartbeat: Mecanisme de comunicació entre els diferents nodes del cluster per monitoritzar i verificar l'estat dels nodes del cluster. Utilitza una xarxa pròpia i exclusiva per on els nodes del cluster es comunicaràn a efectes de mantenir el servei actiu, controlar les fallades. Pot ser un simple ping, o un missatge més complex que inclogui informació adicional del estat i la carrega de cada node.
- Cluster Information Base o CIB: Base de dades del cluster, replicada a tots els nodes, on es guarda la configuració dels recursos del cluster i les seves caracteristiques.
- Agents de tanca (fence agents, en anglés): Els agents de tanca en un clúster són components o programes utilitzats per a garantir la disponibilitat i la integritat dels recursos. S'encarreguen d'aïllar els nodes problemàtics per a evitar que afectin la resta del clúster. Això s'aconsegueix mitjançant mètodes com l'apagat remot o el reinici de nodes, l'aïllament a través d'interruptors d'alimentació o el bloqueig de ports de xarxa. Els agents de clos asseguren l'estabilitat i la continuïtat de les operacions en el clúster, mantenint l'alta disponibilitat i la tolerància a fallades.
Requisits previs
Els requisits per muntar un cluster de hardware son:
- Tenir com a minim 3 nodes
- Tenir una màquina externa que farem servir per connectar-nos i configurar-la
- Software de gestió de clusters (A linux es fa servir ClusterSSH: Això es fa per replicar totes les comandes que es facin en tots els nodes del cluster. A windows podem fer servir cPUTTY)
- El Hardware dels nodes ha de ser identic, en la mesura del possible
- Necessitarem una xarxa exclusiva per comunicació entre nodes
Els requisits desitajs per muntar un cluster de hardware, son, els requisits més:
- El hardware de support, per assegurar el funcionament del cluster, haurà d'estar duplicat (Switchos, tarjes de xarxa, discos durs, fonts d'alimentació)
- Linies de alimentació replicades
- Racks separats per a cada node del cluster
- Sales i/o edificis separats per a cada node del cluster.
Aquest requisits es poden portar fins a la obsessió, i dependrà en gran mesura del grau de disponibilitat i criticitat que necessiti el sistema (es diferent muntar un servei en cluster per aprendre cóm funciona, que un servei en cluster per controlar el tràfic aeri de un aeroport internacional. En aquests casos es pot arribar a posar màquines amb CPU's i memòria replicada, es a dir que si una màquina te 64 Gb de RAM i 4 CPUs, nomes farem servir 32Gb i 2 CPUS les operacions dintre de la màquina estaràn replicades, i en cas de fallada de una CPU o de un mòdul de memòria la màquina seguira funcionant. Ja us he dit que es pot portar fins a l'extrem)
Entorn
Per muntar el nostre entorn farem servir 5 màquines:
- Màquina d'administració, que tindrà entorn gràfic i on instal·larem el software de gestió de cluster (ClusterSSH). nosaltres farem servir un ubuntu desktop. Aquesta màquina només haurà de tenir accés a la xarxa d'administració
- Tres màquines iguals, amb les mateixes definicions de hardware. N'instal·larem la última versió de debian.
En aquestes màquines hi afegirem 3 xarxes:
| Xarxa | Rang | Màscara |
|---|---|---|
| Heartbeat | 192.168.100.8 | /29 |
| Servei | 172.16.84.0 | /24 |
| Administració | 192.168.1.0 | /24 |
- Per provar el servei ho farem a una cinquena màquina, que tindrà accés nomes a la xarxa de servei.
- El software que farem servir està tot als repositoris oficials de debian i/o ubuntu. En cas de fer servir cPutty es pot baixar i fer servir sota Windows.
Esquema
L'esquema final que ens quedarà serà el següent:
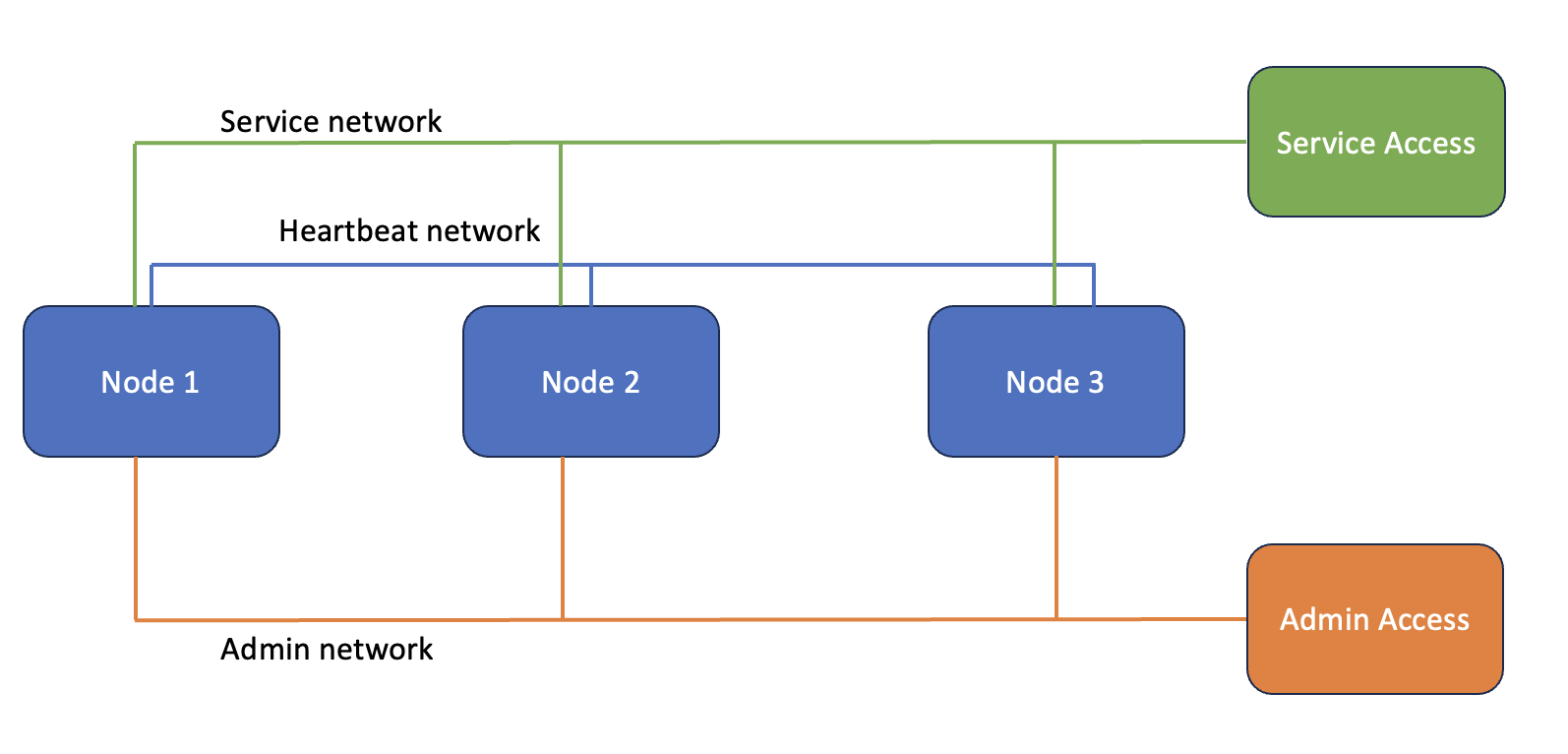
On accedirem al servei des de la màquina Service Access i gestionarem els nodes des de la màquina Admin access
Instal·lació
A efectes de la pràctica farem servir la última versió LTS de Debian pels nodes i la última versió LTS de Ubuntu Desktop per la màquina de gestió i de servei.
Infraestructura
Muntarem la infraestructura a partir de les dades de la següent taula
| Host/Server | IP Administració | IP Servei | IP Heartbeat |
|---|---|---|---|
| Node1 | 192.168.1.11/24 | 172.16.84.11/24 | 192.168.100.11/29 |
| Node2 | 192.168.1.12/24 | 172.16.84.12/24 | 192.168.100.12/29 |
| Node3 | 192.168.1.13/24 | 172.16.84.13/24 | 192.168.100.13/29 |
| ClusterAdm | 192.168.1.20/24 | ||
| ClusterSvc | 172.16.84.20/24 |
Nodes
La instal·lació dels nodes es una instal·lació normal, sense entorn gràfic i amb el servei ssh. En la pràctica ho farem amb un gestor de màquines virtual
Crear una nova màquina
- HDD:24Gb
- Afegir 3 interfícies de xarxa
- Interfície 1: Adaptador pont
- Interfície 2: Xarxa interna 1
- Interfície 3: Xarxa interna 2
- Iniciem la màquina virtual, i anem seleccionant les opcions per defecte. Si l'hem generat correctament, ens haurà d'agafar IP automàticament per l'adaptador de xarxa 1
- Nom de màquina node1
- En la pràctica farem servir tot el disc, guiat, i tots els fitxers en una partició.
- En la selecció de programes, escollirem ÚNICAMENT «ssh server» i «utilitats estàndard del sistema». La resta d'opcions ha de romandre desmarcades.
- La resta d'opcions d'instal·lació queden a criteri de l'usuari.
Un cop la instalació sigui completa, reiniciarem la màquina i comprovarem que funciona correctament, aprofitant per canviar la IP autoasignada per una IP fixe (Un servidor no ha de estar mai configurat per DHCP), modificant el fitxer /etc/network/interfaces, aprofitant per afegir les dues noves xarxes:
/etc/network/interfaces original
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback # The primary network interface allow-hotplug ens160 iface ens160 inet dhcp
/etc/network/interfaces modificat
# This file describes the network interfaces available on your system # and how to activate them. For more information, see interfaces(5). source /etc/network/interfaces.d/* # The loopback network interface auto lo iface lo inet loopback # The primary network interface # allow-hotplug ens160 # iface ens160 inet dhcp #Xarxa de Servei auto ens160 iface ens160 inet static address 172.16.84.11 netmask 255.255.255.0 gateway 172.16.84.2 dns-nameservers 172.16.84.2 1.1.1.1 8.8.8.8 # Xarxa d'administració auto ens161 iface ens161 inet static address 192.168.1.11 nemask 255.255.255.0 # Xarxa de Heartbeat auto ens256 iface ens256 inet static address 192.168.100.11 netmask 255.255.255.248
Un cop fet aquests canvis, reiniciem la màquina i comprovem que s'apliquen els canvis:
abans d'aplicar els canvis
root@node1:~# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:da:2f:f7 brd ff:ff:ff:ff:ff:ff altname enp2s0 inet 172.16.84.139/24 brd 172.16.84.255 scope global dynamic ens160 valid_lft 1603sec preferred_lft 1603sec inet6 fe80::20c:29ff:feda:2ff7/64 scope link valid_lft forever preferred_lft forever 3: ens161: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 00:0c:29:da:2f:0b brd ff:ff:ff:ff:ff:ff altname enp3s0 4: ens256: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000 link/ether 00:0c:29:da:2f:01 brd ff:ff:ff:ff:ff:ff altname enp26s0
després dels canvis
root@node1:~# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens160: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:da:2f:f7 brd ff:ff:ff:ff:ff:ff altname enp2s0 inet 172.16.84.11/24 brd 172.16.84.255 scope global ens160 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:feda:2ff7/64 scope link valid_lft forever preferred_lft forever 3: ens161: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:da:2f:0b brd ff:ff:ff:ff:ff:ff altname enp3s0 inet 192.168.1.11/24 brd 192.168.1.255 scope global ens161 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:feda:2f0b/64 scope link valid_lft forever preferred_lft forever 4: ens256: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000 link/ether 00:0c:29:da:2f:01 brd ff:ff:ff:ff:ff:ff altname enp26s0 inet 192.168.100.11/29 brd 192.168.100.15 scope global ens256 valid_lft forever preferred_lft forever inet6 fe80::20c:29ff:feda:2f01/64 scope link valid_lft forever preferred_lft forever
Replicar el node creat
En aquest punt podem parar la màquina i clonar-la 2 vegades per fer els altres 2 nodes i fem les seguents modificacions:
- Xarxa: Canviem les IP's fixes per IP's acabades en 12 (172.16.84.12/24, 192.168.1.12/24 i 192.168.100.12/29 pel node2 i 172.16.84.13/24, 192.168.1.13/24 i 192.168.100.13/29 pel node3) en el arxiu /etc/network/interfaces
- Nom de màquina: modifiquem el fitxer /etc/hostname canviat el nom a node2/node3
- Canviem el fitxer /etc/hosts:
- Totes les referencies de node1 a node2/node3 i afegim el node1 per la xarxa Heartbeat. Aquest canvi es importantíssim, ja que si no els nodes no es reconeixeran entre ells.
- Afegim els altres dos nodes amb la seva xarxa de heartbeat (192.168.100.8/29)
- Reiniciem les màquines clonades i comprovem que es veuen per totes les xarxes:
ping node1 ping 192.168.1.11 ping 172.16.18.11
- També podem comprovar que la ruta per defecte es la mateixa per totes que tenen visibilitat a internet
ip route ping www.google.com
Si els pings ha estat tots correctes, ja podem deixar les màquines corrent en segon pla, perquè ara muntarem les màquines d'accés. La resta de la configuració i proves les farem des d'aquestes.
Màquina d'administració
A l'hora de crear aquesta màquina tindrem en conte:
- Disc dur: 32 Gb
- Xarxa: La connectem per adaptador pont (En acabar, la connectarem a la xarxa privada d'administració, però ara necessitem instal·lar el ClusterSSH i per tant necessitem que tingui accés al exterior)
També podem aprofitar una màquina que tinguem instal·lada i connectar-la a la xarxa privada d'administració. El que es important es que aquesta màquina vegi per ssh als 3 nodes per la xarxa d'administració.
També hem de tenir present que, quan estigui instal·lada, aquesta màquina no estarà connectada al exterior.
La instal·lació es força directe i no requereix de res en especial. Un cop ja tenim la màquina instal·lada podem instal·lar el ClusterSSH
#apt install clusterssh -y
I canviar la configuració del adaptador de xarxa:
- En el servidor, canviar la configuració de dinàmica a estàtica amb la IP de la xarxa de administració (192.168.1.20/24)
original
- /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity' network: ethernets: ens160: dhcp4: true version: 2
final
- /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity' network: renderer: networkd ethernets: ens160: addresses: - 192.168.1.20/24 nameservers: addresses: [4.2.2.2, 1.1.1.1] version: 2
- En el Hipervisor, connectar el adaptador de xarxa a la xarxa d'administració
- Reiniciar la màquina
Comprovem que podem connectar amb el ClusterSSH als servidors:
ping 192.168.1.11 cssh root@192.168.1.11 root@192.168.1.12 root@192.168.1.13
En arrencar el programa ens trobarem amb una imatge similar a la següent:

On veiem «3 sesions ssh als 3 nodes» i una caixeta petita que posa CSSH[3]:
Tot el que escribim en aquests calaixet s'escriurà a la resta de finestres. Per tant, per assegurar que les màquines son identiques, la configuració, la farem des de aquesta finestreta i la farem servir com un replicador de terminals.
Màquina de servei
Amb la màquina de servei farem el mateix que hem fet amb els nodes, pero aquesta vegada a partir de la màquina d'administració, aplicant els següents canvis:
- Nom de màquina (/etc/hosts i /etc/hostname): clustersvc
- IP: 172.16.84.20/24
- Adaptador de xarxa, connectat a la xarxa de servei
Provarem de fer ping als nodes per la xarxa de servei:
ping 172.16.84.11 ping 172.16.84.12 ping 172.16.84.13
I si funciona, podem deixar la infraestructura per muntada i acabada.
Ara passarem a la instal·lació del software
Software
Cluster
A partir de la consola de ClusterSSH executarem concurrentment en els 3 nodes les següents comandes:
# Actualitzem el sistema a ultimes versions apt update && apt upgrade # Instal·lem el servei de cluster apt install pacemaker crmsh # Instal·lem un servei per afegir-lo al cluster apt install nginx # Tot i que el desabilitem de l'arrencada de la màquina systemctl disable nginx # I deshabilitem el servei de cluster mentre no el tenim configurat systemctl disable pacemaker
Ara, i abans de posar en marxa el cluster hem de fer unes modificacions als arxius de configuració del cluster:
original
- /etc/corosync/corosync.conf
crypto_cipher: none crypto_hash: none
modificat
- /etc/corosync/corosync.conf
crypto_cipher: aes256 crypto_hash: sha1
I, en el apartat nodelist, hem d'afegir informació pels 3 nodes, tenint en conte que la informació ha de ser la mateixa pels 3 nodes, i posant la informació de la xarxa de heartbeat.
original
- /etc/corosync/corosync.conf
nodelist { # Change/uncomment/add node sections to match cluster configuration node { # Hostname of the node name: node1 # Cluster membership node identifier nodeid: 1 # Address of first link ring0_addr: 127.0.0.1 # When knet transport is used it's possible to define up to 8 links #ring1_addr: 192.168.1.1 } # ... }
modificat
- /etc/corosync/corosync.conf
nodelist { # Change/uncomment/add node sections to match cluster configuration node { # Hostname of the node name: node1 # Cluster membership node identifier nodeid: 1 # Address of first link ring0_addr: 192.168.100.11 # When knet transport is used it's possible to define up to 8 links #ring1_addr: 192.168.1.1 } node { # Hostname of the node name: node2 # Cluster membership node identifier nodeid: 2 # Address of first link ring0_addr: 192.168.100.12 # When knet transport is used it's possible to define up to 8 links #ring1_addr: 192.168.1.1 } node { # Hostname of the node name: node3 # Cluster membership node identifier nodeid: 3 # Address of first link ring0_addr: 192.168.100.13 # When knet transport is used it's possible to define up to 8 links #ring1_addr: 192.168.1.1 } }
També podem canviar el nom del cluster i posar-li el que volguem:
cluster_name: NomDelCluster
Clau privada del cluster
Per tal de assegurar que els cluster comparteixen clau segura s'ha de generar aquesta clau i propagar-la a tots els nodes del cluster, per fe aixo, ho farem des del Node1 Exclusivament, es a dir, que obrirem una sessió ssh capa el node1 per fer aquesta operativa i executarem:
corosync-keygen
, i propagarem la clau generada als altres dos nodes: (Recordeu que, per habilitar la còpia via ssh s'ha d'habilitar la opció PermitRootLogin yes del fitxer /etc/ssh/sshd_config)
scp /etc/corosync/authkey root@node2:/etc/corosync/authkey scp /etc/corosync/authkey root@node3:/etc/corosync/authkey
Un cop copiada la clau, podem engegar el cluster
systemctl start corosync systemctl start pacemaker
I comprovar que els serveis estan engegats
# crm status Status of pacemakerd: 'Pacemaker is running' (last updated 2023-07-01 21:23:43 +02:00) Cluster Summary: * Stack: corosync * Current DC: node2 (version 2.1.5-a3f44794f94) - partition with quorum * Last updated: Sat Jul 1 21:23:43 2023 * Last change: Sat Jul 1 21:15:39 2023 by hacluster via crmd on node2 * 3 nodes configured * 0 resource instances configured Node List: * Online: [ node1 node2 node3 ] Full List of Resources: * No resources
Ara ja tenim el cluster creat. Només falta afegir serveis al cluster
Serveis
Introducció
Els serveis del cluster, també anomenats recursos, son els recursos que s'aniràn migrant de node a node mentre estigui el cluster disponible.
Per afegir els recursos, ho farem des de una màquina i fent servir l'entorn que corosync ens posa a disposició per editar-los. Aquest es la shell crm (Cluster Resource Manager)
crm
Amb aquesta shell podem fer servir el tabulador per saber les opcions que tenim disponibles i per finalitzar les paraules que volem pasar-li, podem fer servir la comanda help per mostrar ajuda sobre les comandes.
N'afegirem els següents recursos:
- IP flotant que ens donarà el servei al servidor Web (!72.16.84.10/24)
- El servei web mateix (Nginx)
- Els agents de tanca dels nodes (fence_node1, fence_node2, fence_node3): Aquests agents es faran correr en els nodes que vigilen el node vallat, es a dir, en els nodes que no apareixen al nom del agent.
IP i Nginx
Obrim crm configure:
crm configure
I executem les seguents comandes per habilitar el agents de tanca més endavant (stonith-enable) i habilitar que el cluster continui funcionant amb un sol node (no-quorum-policy)
≤code bash> crm(live/node1)configure#
property stonith-enabled=no
property no-quorum-policy=ignore
</code>
Ara, afegim els recursos per l'nginx (Aquest nginx l'hem instal·lat en el pas de generació de nodes, previament):
Recorda, que si les teves IP's son diferents, les has de modificar, i has de definir l'adaptador que correspongui (Hauria de ser el mateix a tots els nodes!!!)
crm(live/node1)configure# primitive IP-nginx ocf:heartbeat:IPaddr2 params ip="172.16.84.10" nic="ens160" cidr_netmask="24" meta migration-threshold=2 op monitor interval=20 timeout=60 on-fail=restart crm(live/node1)configure# primitive Nginx-rsc ocf:heartbeat:nginx meta migration-threshold=2 option monitor interval=20 timeout=60 on-fail=restart crm(live/node1)configure# colocation lb-loc inf: IP-nginx Nginx-rsc crm(live/node1)configure# order lb-ord inf: IP-nginx Nginx-rsc crm(live/node1)configure# commit
Amb això, hem creat 2 recursos (IP-nginx i Nginx-rsc) i hem definit que:
- Els dos recursos corrin al mateix node
- La IP sempre estigui disponible
Si en qualsevol moment ens equivoquem a l'hora de generar els recursos, (ens apareix qualsevol error per pantalla):
- Haurem de parar el recurs:
crm(live/node1)configure# up resource stop "nom_del_recurs" configure delete "nom_del_recurs" commit
- Regenerar el recurs correctament i les subseqüents comandes.
Agents de tanca
La tanca es posa, perque, en cas que hi hagi un node malfuncionant per qualsevol motiu, es pugui aïllar del cluster
Per evitar tocar la base de dades del cluster, i liar-la parda, primer generarem una CIB de proves (Shadow cib)
crm(live/node1)# cib new fencing INFO: cib.new: fencing shadow CIB created crm(fencing/node1)#
Per veure quins agents de stonith tenim, podem executar des de la linia de comandes de qualsevol node:
stonith_admin -I
Hi ha molts. Els executables son a /usr/sbin i al man de cada un d'ells surten les opcions que s'hi poden fer servir.
Nosaltres farem servir fence_virsh, asumint que els nostres nodes son accesssibles via ssh, i hem habilitat l'access com a root. Si no fos així hauriem de configurar sudo per permetre que un usuari pogues executar les accions del cluster.
crm(fencing/node1)# configure crm(fencing/node1)configure# property stonith-enabled=yes crm(fencing/node1)configure# primitive fence_node01 stonith:fence_virsh params ipaddr=172.16.84.11 port=node1 action=off login=root passwd=Hola123 op monitor interval=60s crm(fencing/node1)configure# primitive fence_node02 stonith:fence_virsh params ipaddr=172.16.84.12 port=node2 action=off login=root passwd=Hola123 op monitor interval=60s crm(fencing/node1)configure# primitive fence_node03 stonith:fence_virsh params ipaddr=172.16.84.13 port=node3 action=off login=root passwd=Hola123 op monitor interval=60s crm(fencing/node1)configure# location l_fence_node01 fence_node01 -inf: node1 crm(fencing/node1)configure# location l_fence_node02 fence_node02 -inf: node2 crm(fencing/node1)configure# location l_fence_node03 fence_node03 -inf: node3 commit
Amb això ja tindriem generats els agents de tanca. Podem simular el funcionament amb la nova cib:
crm(fencing/node1)configure# cib cibstatus simulate Current cluster status: * Node List: * Online: [ node1 node2 node3 ] * Full List of Resources: * IP-nginx (ocf:heartbeat:IPaddr2): Started node2 * Nginx-rsc (ocf:heartbeat:nginx): Started node2 * fence_node01 (stonith:fence_virsh): Stopped * fence_node02 (stonith:fence_virsh): Stopped * fence_node03 (stonith:fence_virsh): Stopped Transition Summary: * Start fence_node01 ( node3 ) * Start fence_node02 ( node1 ) * Start fence_node03 ( node1 ) Executing Cluster Transition: * Resource action: fence_node01 monitor on node3 * Resource action: fence_node01 monitor on node2 * Resource action: fence_node01 monitor on node1 * Resource action: fence_node02 monitor on node3 * Resource action: fence_node02 monitor on node2 * Resource action: fence_node02 monitor on node1 * Resource action: fence_node03 monitor on node3 * Resource action: fence_node03 monitor on node2 * Resource action: fence_node03 monitor on node1 * Resource action: fence_node01 start on node3 * Resource action: fence_node02 start on node1 * Resource action: fence_node03 start on node1 * Resource action: fence_node01 monitor=60000 on node3 * Resource action: fence_node02 monitor=60000 on node1 * Resource action: fence_node03 monitor=60000 on node1 Revised Cluster Status: * Node List: * Online: [ node1 node2 node3 ] * Full List of Resources: * IP-nginx (ocf:heartbeat:IPaddr2): Started node2 * Nginx-rsc (ocf:heartbeat:nginx): Started node2 * fence_node01 (stonith:fence_virsh): Started node3 * fence_node02 (stonith:fence_virsh): Started node1 * fence_node03 (stonith:fence_virsh): Started node1
I, si tot sembla correcte, podem pasar els canvis a producció:
crm(fencing/node1)configure# cib commit INFO: configure.cib.commit: committed 'fencing' shadow CIB to the cluster crm(fencing/node1)configure# cib use crm(live/node1)configure#
Per fer un check de l'status podem fer-ho amb **crm status*
que ens haurà de donar un resultat semblant al següent:
crm_mon Cluster Summary: * Stack: corosync * Current DC: node2 (version 2.1.5-a3f44794f94) - partition with quorum * Last updated: Mon Jul 3 08:41:48 2023 * Last change: Mon Jul 3 08:40:06 2023 by root via cibadmin on node1 * 3 nodes configured * 5 resource instances configured Node List: * Online: [ node1 node2 node3 ] Active Resources: * IP-nginx (ocf:heartbeat:IPaddr2): Started node2 * Nginx-rsc (ocf:heartbeat:nginx): Started node2 * fence_node01 (stonith:fence_virsh): Started node3 * fence_node02 (stonith:fence_virsh): Started node1 * fence_node03 (stonith:fence_virsh): Started node1
Amb això ja tindrem el nostre Nginx en cluster corrent en 3 nodes, i podem jugar tancant i encenent nodes i comprovar com l'Nginx continua funcionant independentment del node on corri.
Referències
https://github.com/dprokscha/cputty
https://inlab.fib.upc.edu/es/blog/pacemaker-alta-disponibilidad-para-linux